Ahora
queremos estudiar como se pueden agrupar los discos entre si para mejorar sus
características, son los llamados RAID (Redundant
Array of Independent Disks). Una vez
más entran en juego los factores de seguridad, capacidad y velocidad. Según la
funcionalidad y los tipos de controladoras nos permitirán configurar unos u
otros, siendo los más habituales:
RAID 0: Sin nivel de seguridad, cada agrupación
tiene su capacidad y su rendimiento.

RAID 1: Discos en espejo. Se escribe
exactamente lo mismo en todos los discos del RAID. Esta opción es la correcta
cuando prima la seguridad frente al rendimiento y capacidad. Sin embargo, en la
actualidad las cabinas y controladoras son capaces de hacer splitting y aprovechar los cabezales
para leer datos entre los distintos discos de forma simultánea mejorando así el
rendimiento de forma lineal. Es la opción más acertada para el almacenamiento
de una base de datos de producción.

RAID 5: Esta formado por tres discos como
mínimo. Es capaz de aprovechar mejor el espacio de almacenamiento en detrimento
del rendimiento ya que las escrituras son más costosas. Se suele montar en
entornos no muy críticos donde prima el aprovechamiento del espacio frente a
seguridad y rendimiento, por ejemplo en los repositorios de software.

Posteriormente
han ido apareciendo otras múltiples agrupaciones más complejas, siendo las más
comunes:
RAID 3: Similar a RAID 0 pero se añade un
disco de paridad. Tiene baja seguridad y bajo rendimiento ya que no se puede
leer y escribir a la vez, provoca muchos cuellos de botella. Sin embargo, se
aprovecha el 75% de almacenamiento bruto en un caso con 4 discos.

RAID 4: Mismo concepto que RAID 3 pero en
este caso el acceso a los discos es independiente con lo que podemos leer y
escribir en distintos discos a la vez.
Esto es posible porque la información se guarda a nivel de bloque en
lugar de hacerlo en bytes como en RAID 3.

RAID 6: Igual que el RAID 5 pero añadiendo
otro bloque de paridad, el rendimiento es mejor en las lecturas pero penalizas
las escrituras al tener que estar calculando dos bits de paridad. Mejoras en
seguridad pero disminuye el aprovechamiento del espacio.

Y por último
existen los niveles RAID anidados, siendo los más usados:
RAID 0+1: Es un espejo de divisiones. Varios
discos se agrupan en RAID 0 y luego se replica el grupo en otro grupo espejo.

RAID 1+0: Es una división de espejos. Igual
que la agrupación anterior pero se invierten los RAID. Son muy usados en
entornos de producción que requieran rendimiento. La única pega es que no
permite salvaguardar los datos cuando se produce un doble fallo.

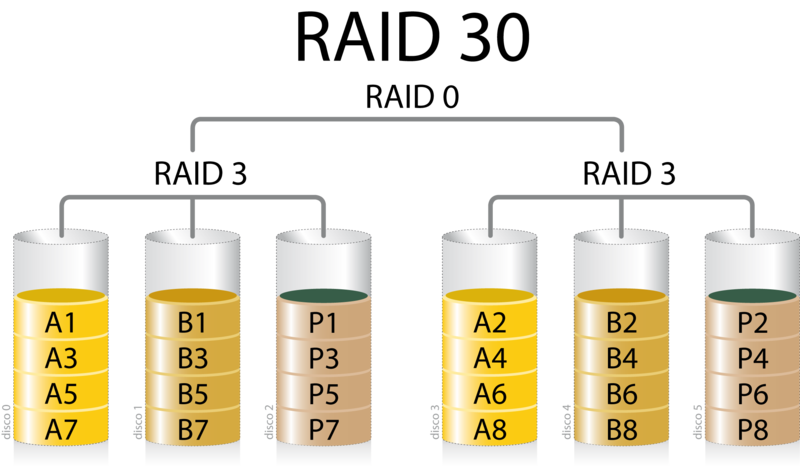
RAID 30: Es una agrupación en Raid 0 de dos
conjuntos Raid 3. Rendimiento similar al Raid 3 pero se añade seguridad al
conjunto ya que puede fallar un disco de cada grupo.
RAID 50: Misma idea que los Raid 30 pero
haciendo la división Raid 5.

RAID 10+0: En realidad es un 1+0+0, es decir,
una división más de un RAID 1+0. Son los llamados RAID cuadriculados. Se
utiliza en entornos que requieran gran tamaño con buen rendimiento, como pueden
ser grandes bases de datos.

RAID 10+1: Es un espejo de un RAID 1+0,
también llamado Network Raid. Se suele utilizar en la replicación de cabinas en
entornos críticos.
Gracias, Wikipedia, por prestarme estos gráficos tan útiles.
Texto extraído de mi proyecto final de carrera: Implantación de una SAN corporativa.













.png)
